Machine Learning Primer
Neural networks
The technological advancements of the late 20th century paved the way for large scale data processing units capable of running multiple tasks in parallel. Compute paralellization led to the adoption of new techniques for data analysis developed throughout the second half of the 20th century, the most prominent of which being the introduction of the multi-layer perceptron. The perceptron was inspired by the function of the neuron as the fundamental processing unit in the human brain, where each node or “neuron” in a network can be thought of as executing some transformation of its input data before passing the signal forward to its neighbors. Nowadays we see extremely complex AI architectures that emulate many components of biological cognition, (e.g. attention, memory, etc.), however, the core component of these networks is still a relatively simple neuron architecture that simply takes in an input and performs a transformation to it before passing it along.
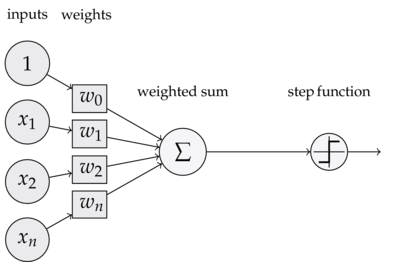
The above figure shows the structure and function of a single perceptron, with input data coming in from the left, weighted by some parameter w (just a multiplication operation), summed over, and scaled with the so called “activation function”, which in this case is just a step function, meaning the output of this particular neuron will be one of two numbers (usually -1 and 1 or 0 and 1). Other activation functions can be used, the output does not have to be binary. By stacking many of these neurons together, we can form a “neural network” which can learn representations of high dimensional data. Neural networks are currently ubiquitous in data science thanks to their ability to learn complex representations from vast amounts of data. In physics, neural networks are particularly helpful in particle physics, in which experiments such as ATLAS produce vast amounts of data that cannot be parsed by a single team of scientists. In the following notebooks, we’ll explore applications of neural networks in particle physics.
Data in machine learning
Neural networks form only a small portion of the development and research work done by data scientists or physicists using data science in their data exploration. The bulk of the work consists of preprocessing the dataset to make sure only clean and relevant data gets sent to the final neural network.
A particular practice relevant in the following notebooks is the notion of creating a train/test/validation splits. In a supervised learning task (task in which the neural network learns by making predictions and comparing them to the true target values), we want a robust way to evaluate whether our model is able to generalize to data beyond that contained in its training dataset. As a result, whenever we have a dataset we want to train our machine learning model on, we usually split it into one or two subsets so that one of these subsets is used for purely for training and the others are used purely for validation/testing of the performance of our model (a separate validation set is often used when comparing multiple models; in a simple one-model case, it is sufficient to use a train-test split).
Once we have our training and testing subsets, there are a number of other preprocessing steps we might want to take to increase the likelihood that our model will learn meaningful, general characteristics of our data (as opposed to highly specialized, but ultimately unusable ones). One such technique which we’re going to see in the following notebooks is random shuffling and batch splitting. Random shuffling of our data is an important step that helps to reduce the likelihood that our model will start learning the sequential patterns in our data. Now, this might be a property we actually want the model to learn (particularly if we’re interested in time-series data), it depends entirely on the task/problem at hand. In the Quark Tagging notebook, we want the model to learn whether a given jet represents a top-quark or a background signal and so it does not matter which signal came before. Batch splitting is a technique to chunk our dataset into small segments that efficiently fit into computer memory. This increases the speed with which we can train our models as well as allows the model to learn from sparse data at any given timestep, the idea being that by presenting only a small subset of data to the neural network, it is more likely to learn high-level properties that are ubiquitous within this particular domain.